Fórum:Testy2/Teorie odpovědi na položku


Klasické odhady obtížnosti, citlivosti, ale i spolehlivosti jsou silně závislé na rozdělení znalostí u testované skupiny. Představme si dvě skupiny studentů – horší a lepší. Použijeme-li klasického odhadu obtížnosti, ve skupině lepších studentů se položka bude jevit jako snadná a naopak ve skupině slabších studentů se bude jevit jako obtížná (viz obr. 8.15a, 8.15b).
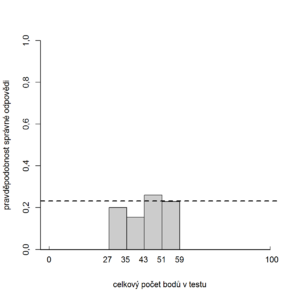
Obr. 8.15a Klasický odhad obtížnosti položky pro horší skupinu
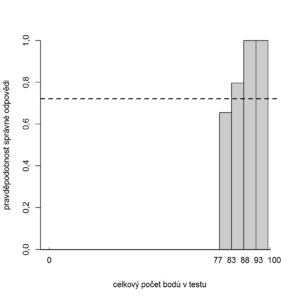
Obr. 8.15b Klasický odhad obtížnosti položky pro lepší skupinu


To může být problém, pokud používáme položku pro různé skupiny studentů, např. sdílíme-li položky s dalšími fakultami. Proto se v případě většího počtu studentů nebo skupin studentů používá modernější teorie odpovědi na položku (angl. item response theory, IRT), která modeluje pravděpodobnost správného zodpovězení položky podmíněně pro různé úrovně znalosti studenta.
Zjednodušeně řečeno, vztah relativní četnosti správné odpovědi na položku a celkového počtu bodů, který jsme v předchozí kapitole ilustrovali sloupcovým grafem, v rámci teorie odpovědi na položku modelujeme spojitou funkcí zvanou charakteristická funkce položky (angl. item characteristic function, ICF).

Pokud tedy budeme odhadovat obtížnost položky z odpovědí u skupiny slabších studentů, IRT odhad vezme v potaz úroveň znalosti studentů a odhaduje spodní část křivky. Pokud získáme výsledky od skupiny lepších studentů, je odhadována horní část křivky. Výsledné křivky (potažmo parametry obtížnosti) odhadnuté dle dvou skupin studentů si nakonec mohou být velice blízké a téměř totožné s křivkou, kterou bychom dostali, pokud bychom odhadovali ze všech dat najednou (viz obr. 8.17).

 |
Tip: Klasické odhady obtížnosti a citlivosti položky neberou v potaz rozdělení znalostí v testované skupině. Jsou-li položky používány pro velké množství studentů různých znalostních úrovní, je vhodné klasické odhady nahradit IRT odhady. |
|
Klasický odhad obtížnosti je založený na relativní četnosti správných odpovědí v testované skupině. Tento údaj však nemusí být relevantní, použijeme-li položku pro skupinu s jiným rozdělením znalosti. IRT modely popisují obtížnost v závislosti na znalosti studenta. |
| Tip: Klasické odhady obtížnosti a citlivosti položky neberou v potaz rozdělení znalostí v testované skupině. Jsou-li položky používány pro velké množství studentů různých znalostních úrovní, je vhodné klasické odhady nahradit IRT odhady. |
